



不均衡データの取り扱い
- HiSR

- 2022年5月11日
- 読了時間: 4分
更新日:2022年6月23日
✔︎HPもぜひご覧ください : https://www.hrl.jp/
不均衡データとはデータが顕著に偏っているインバランスなデータ群を言います。不均衡データを取り扱う際は適切な処理を施さなければ適切な分類ができない可能性が考えられます。具体的には大多数を占めるクラスに偏った推定結果となり, 小数データの精度が著しく低くなる傾向が見られます。しかしながら現実世界のタスクでは不均衡データであることが珍しくありません。例えば医療検査データのように大部分が正常, あるいは希少な疾患を検出する必要がある場合, 不均衡の状態になる可能性が高いと考えられます。このような状況を改善する手法がいくつか提案されていますので以下に説明します。
1. サンプリング
不均衡データセットからサンプリングを行い,クラス比率のバランスが取れたデータセットを作成する。
・Undersampling : 大多数の正常サンプルを削減
・Oversampling : 少数の異常サンプルを水増し
2. 損失関数の重み調整
正常サンプルを異常と誤分類した際のペナルティを小さく,異常サンプルを正常と誤分類した際のペナルティを大きくする。
例えば,サンプル数の存在比率の逆数を重みとして利用する。
3. 目的関数(損失関数)の変更
異常サンプルに対する予測スコアを向上させるような目的関数を導入する。
4. 異常検知
正常サンプルのデータ分布を仮定し,そこから十分に逸脱したサンプルを異常とみなす。

ここでは一般的によく使用される, 1. サンプリング, 3. 目的関数の変更について
解説します。
▶︎サンプリング・・・UndersamplingとOversamplingを組み合わせることで,
データセットの不均衡を低減します。
今回は以下のステップでサンプリングを行います。
Undersamplingにより,正常サンプルのみ1/nに削減
単純なランダムサンプリングを採用します。ランダム性があるため,分類にとって重要なサンプルを削除してしまう可能性があります。
ランダムサンプリングの問題を緩和する手法も幾つか存在します。
Oversamplingにより,Undersampling後の正常サンプルと同数になるまで異常サンプルを水増しします。
一般的にSMOTE (Synthetic Minority Over-sampling TEchnique) が使われることが多いかと思われます(Fig. 1)。
ランダムにデータを水増しする最も単純な方法だと,過学習を引き起こしやすくなります。SMOTEでは,VEBサンプルと,その近傍VEBサンプルとの間のデータ点をランダムに生成してデータに追加していくことで,過学習の影響を緩和しています。
SMOTEとその拡張
・Oversamplingするインスタンス(データ点)の初期選択
・Undersamplingとの統合
・補間の種類
・次元変更を伴う操作
・人工データに対する適応的生成
・Relabeling
・ノイズの多い生成データに対するフィルタリング
SMOTEライブラリ
imbalanced-learn は「不均衡データ」を扱うライブラリでオーバーサンプリング
やアンダーサンプリングなどを簡単に実装できます。またSMOTEの派生として,
ADASYN, Borderline SMOTE, Safe-level SMOTEなどがあります
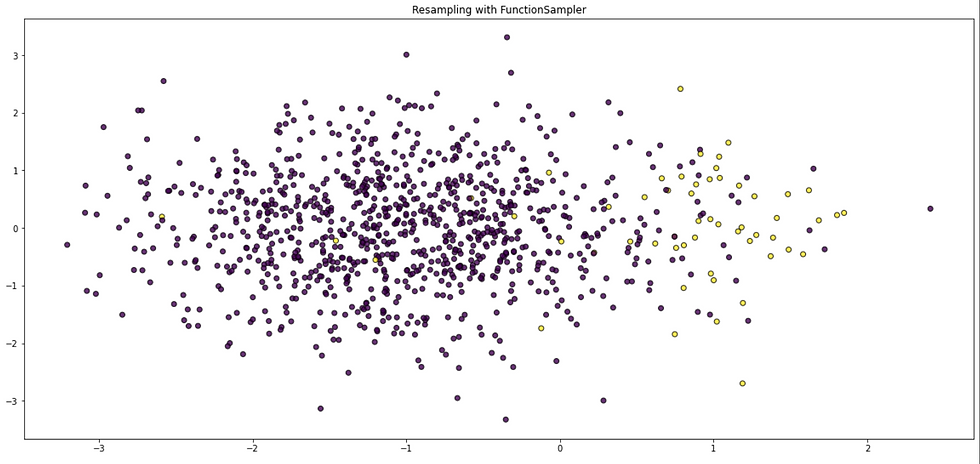

Fig. 1 SMOTEを用いたOversampling例(上図:通常分布, 下図:SMOTEによるOversampling)

▶︎目的関数の変更
少数クラスの予測精度向上に注目した損失関数はこれまでに幾つも提案されていますが,ここではFocal lossという損失関数を解説します。
Focal lossは画像の物体検知の研究で提案された損失関数です。One-stage物体検知手法において,大量の候補領域の中で実際に物体が存在する領域は数個であることが多く,不均衡なタスクになっており,学習がうまく進まないという問題があります。こうした問題を改善するために提案されたのがfocal lossであり,以下の式によって記述されます。

ここでptはSoftmax関数の出力(確率値)です.γ=0の場合,通常のSoftmax cross-entorpy lossと等しくなりますが,γ>0の場合,明確に分類可能なサンプルに対して,相対損失を小さくする効果があります。その結果,分類が難しいサンプルにより注目して学習が進んでいくことが期待されます。下図は正解クラスの予測確率値とその際の損失の関係をプロットしており,γの値を変化させた場合に相対損失がどのように下がっていくかを示しています。

参考文献
*1 Fern ́andez et al., SMOTE for Learning from Imbalanced Data: Progress and Challenges, Marking the 15-year Anniversary, 2018
*2 Lin et al., Focal Loss for Dense Object Detection, 2018
✔︎HPもぜひご覧ください : https://www.hrl.jp/


コメント